
The following article is a part of my Big Data Management RDBMS Project written in SQL and executed in MySQL. Requirements of the project included finding a relatively large dataset and performing data analysis queries on it.
Data Collection
The datasets of Amazon Prime are obtained from Kaggle where it contains two .CSV files which are the titles and credits. The title consists of 15 columns and 9000+ rows including the column name such as movie_id, title, type, descriptions, release_year, age_certification, runtime, genres, production_countries, seasons, imdb_id, imdb_score, imdb_votes, tmdb_popularity and tmdb_score. The credits file consists of 5 columns and 120k+ rows with columns person_id, movie_id, person_name, character_name and roles. Since the columns release_year, age_certification, runtime, seasons, imdb_score, imdb_votes, tmdb_popularity and tmdb_score are numeric in nature, it is possible to derive statistical metrics from the dataset. Figure 1 and Figure 2 shows the snippets of the titles and credits file.
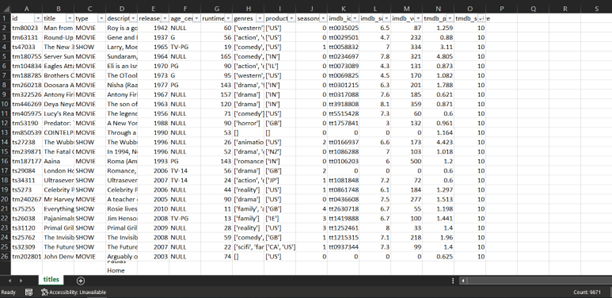 Figure 1: Snippet of titles file. Total row count is displayed on bottom right of the file
Figure 1: Snippet of titles file. Total row count is displayed on bottom right of the file
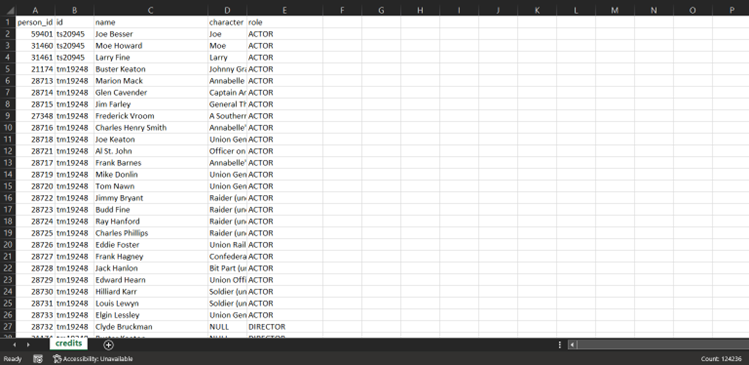 Figure 2: Snippet of credits file. Total row count is displayed on bottom right of the file
Figure 2: Snippet of credits file. Total row count is displayed on bottom right of the file
In order to avoid a cluttered dataset, the 2 CSV files from Figure 1 and Figure 2 are further split up resulting in a total of 6 CSV files which will form the basis of the Entity Relationship Diagram (ERD) used in this project. The breakdown of the resulting 6 CSV files is as below,
- The first file is named “titles”. In it contains only the “title_id” and “title”. This file is derived from the first and second column of the parent file “titles” (Figure 1). A duplication check is also performed on the first column to ensure non-repeating id. The resultant file is made up of 9867 rows and 2 columns. The snippet of “titles” file is depicted in Figure 3.
 Figure 3: Snippet of “titles” file
Figure 3: Snippet of “titles” file
- The second file is named “titles_info” and like the name suggests, it only displays key information on the title. This file is derived from the columns “id”, “type”, “description”, “release_year”, “age_certification”, “runtime”, “genres”, “production_countries” and “seasons” of the parent file “titles” (Figure 1). The resultant file consists of 9867 rows and 9 columns. The snippet of “titles_info” file is illustrated in Figure 4.
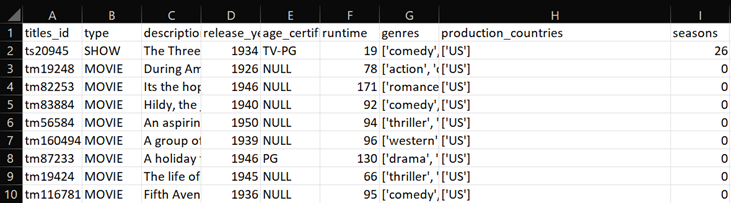 Figure 4: Snippet of “titles_info” file
Figure 4: Snippet of “titles_info” file
- The third file is named “imdb_rating” where this file only contains imdb rating information and is linked through other files by “title_id”. This file is derived from the columns “id”, “imdb_id”, “imdb_score” and “imdb_votes” from the parent file “titles” (Figure 1). This results in a total of 9867 rows and 4 columns. The snippet of “imdb_ratings” file is depicted in Figure 5.
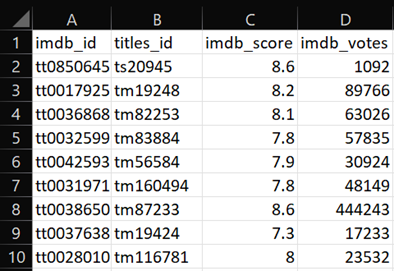 Figure 5: Snippet of “imdb_rating” file
Figure 5: Snippet of “imdb_rating” file
- The fourth file is named “tmdb_rating” which contains information on tmdb ratings and linked through other files by “title_id”. This file is derived from the columns “id”, “tmdb_popularity” and “tmdb_score” from the parent file “titles” (Figure 1). This file consists of 9870 rows and 3 columns. The snippet of “tmdb_rating” file is illustrated in Figure 6.
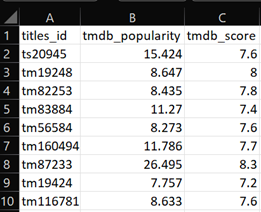 Figure 6: Snippet of “tmdb_rating” file
Figure 6: Snippet of “tmdb_rating” file
- The fifth file is named “actors” which has the names of actors and is linked through other files by “actor_id”. This file is derived from the columns “person_id” and “name” from the parent file “credits” (Figure 2). This file is made up of 80508 rows and 2 columns. The snippet of “actors” is depicted in Figure 7.
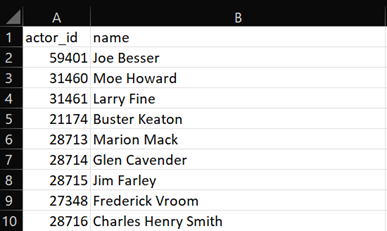 Figure 7: Snippet of “actors” file
Figure 7: Snippet of “actors” file
- The sixth and final file is named “acting_credits” which has the information of characters and the roles they play, while being linked to other files through “actor_id” and “titles_id”. This file is derived from the columns “person_id”, “id”, “character” and “role” from the parent file “credits” (Figure 2). This file consists 124234 rows and 4 columns. The snippet of “acting_credits” is depicted in Figure 8.
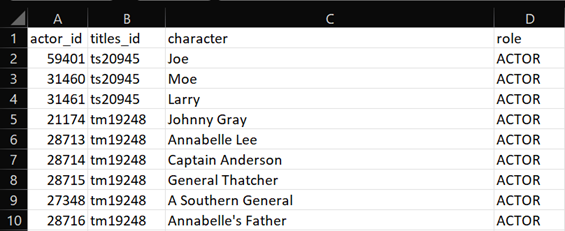 Figure 8: Snippet of “acting_credits” file
Figure 8: Snippet of “acting_credits” file
Entity Relationship Diagram (ERD)
The ERD for this project is illustrated in Figure 9 with the Primary Key (PK), Foreign Key (FK) and their respective Cardinality (Crow’s Foot Notation) according to the legends respectively.
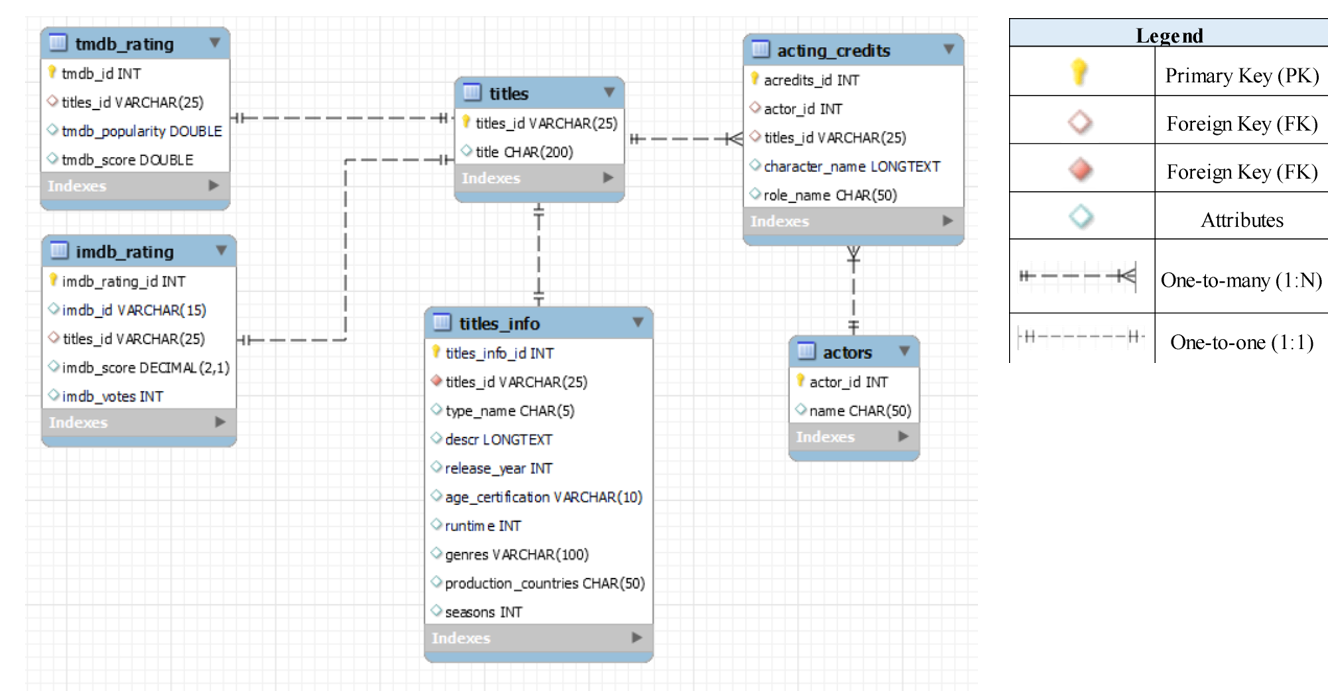 Figure 9: The Entity Relationship Diagram (ERD)
Figure 9: The Entity Relationship Diagram (ERD)
The entities from Figure 9 are described as below,
- (a) actors
- In this entity, there are two attributes which are actor_id (PK) and name. This entity has a cardinality of one-to-many (1:N) with the entity acting_credits. This means that each actor can have many acting credits, but each acting credit can only be linked to one actor.
- (b) acting_credits
- In this entity, there are five attributes which are acredits_id (PK), actor_id (FK referenced from entity actors), titles_id (FK referenced from entity titles), character_name and role_name. This entity has a cardinality of one-to-many (1:N) with the entity titles. This means that each title can have many acting credits, but each acting credit can only be linked to one title. Other than that, this entity also has a one-to-many (1:N) cardinality with the entity actors, meaning that each actor can have many acting credits, but each acting credit can only be linked to one actor.
- (c) titles
- In this entity, there are two attributes which are titles_id (PK) and title. This entity has a cardinality of one-to-many (1:N) with the entity acting_credits. This means that each title can have many acting credits, but each acting credit can only be linked to one title. Apart from that, this entity also has a cardinality of one-to-one (1:1) with the entity titles_info meaning that each title can only have one title info and each title info can only belong to one title. Other than that, this entity also has a cardinality of one-to-one (1:1) with the entity tmdb_rating. This means that each title can have only one tmdb rating and each tmdb rating belongs to only one title. Lastly, this entity has a cardinality of one-to-one (1:1) with the entity imdb_rating. This means that each title can have only one imdb rating and each imdb rating belongs to only one title.
- (d) titles_info
- In this entity, there are ten attributes which are titles_info_id (PK), titles_id (FK referenced from entity titles), type_name, descr, release_year, age_certification, runtime, genres, production_countries and seasons. This entity has a cardinality of one-to-one (1:1) with the entity titles meaning that each title can only have one title info and each title info can only belong to one title.
- (e) tmdb_rating
- In this entity, there are four attributes which are tmdb_id (PK), titles_id (FK referenced from entity titles), tmdb_popularity and tmdb_score. This entity has a cardinality of one-to-one (1:1) with the entity titles. This means that each title can have only one tmdb rating and each tmdb rating belongs to only one title.
- (f) imdb_rating
- In this entity, there are five attributes which are imdb_rating_id (PK), titles_id (FK referenced from entity titles), imdb_id, imdb_score and imdb_votes. This entity has a cardinality of one-to-one (1:1) with the entity titles. This means that each title can have only one imdb rating and each imdb rating belongs to only one title.
The SQL queries in defining the database and the entities are shown below,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
/*Define database*/
CREATE DATABASE Amazon_Prime;
/*Use Database*/
USE Amazon_Prime;
/*Define entity actors*/
CREATE TABLE actors(
actor_id INT(11) PRIMARY KEY,
name CHAR(50)
);
/*Define entity titles*/
CREATE TABLE titles(
titles_id VARCHAR(25) PRIMARY KEY,
title CHAR(200)
);
/*Define entity acting_credits*/
CREATE TABLE acting_credits(
acredits_id INT(25) AUTO_INCREMENT PRIMARY KEY,
actor_id INT(11),
titles_id VARCHAR(25),
character_name LONGTEXT,
role_name CHAR(50),
FOREIGN KEY (actor_id) REFERENCES actors(actor_id)
ON DELETE CASCADE ON UPDATE CASCADE,
);
/*Define entity titles_info*/
CREATE TABLE titles_info(
titles_info_id INT(25) AUTO_INCREMENT PRIMARY KEY,
titles_id VARCHAR(25),
type_name CHAR(5),
descr LONGTEXT,
release_year INT(4),
age_certification VARCHAR(10),
runtime INT(3),
genres VARCHAR(100),
production_countries CHAR(50),
seasons INT(2),
FOREIGN KEY (titles_id) REFERENCES titles(titles_id)
ON DELETE CASCADE ON UPDATE CASCADE
);
/*Define entity imdb_rating*/
CREATE TABLE imdb_rating(
imdb_rating_id INT(25) AUTO_INCREMENT PRIMARY KEY,
imdb_id VARCHAR(15),
titles_id VARCHAR(25),
imdb_score DECIMAL(2,1),
imdb_votes INT(7),
FOREIGN KEY (titles_id) REFERENCES titles(titles_id)
ON DELETE CASCADE ON UPDATE CASCADE
);
/*Define entity tmdb_rating*/
CREATE TABLE tmdb_rating(
tmdb_id INT(25) AUTO_INCREMENT PRIMARY KEY,
titles_id VARCHAR(25),
tmdb_popularity DOUBLE,
tmdb_score DOUBLE,
FOREIGN KEY (titles_id) REFERENCES titles(titles_id)
ON DELETE CASCADE ON UPDATE CASCADE
);
For the purposes of importing the data for each individual entity, it is possible to manually upload each entity’s data using MySQL Workbench. However, I found this process to be extremely time consuming and resorted to bulk transfer the data using a custom Python script instead (which saved me several hours). The aforementioned Python script is as below,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
from tqdm import tqdm
import csv
import sys
import MySQLdb
conn = MySQLdb.connect(host="127.0.0.1", user="username", password="password",
database="amazon_prime")
cursor = conn.cursor()
csv_data = csv.reader(open('acting_credits.csv'))
header = next(csv_data)
print('Importing the CSV Files')
for row in tqdm(csv_data):
#print(row)
cursor.execute(
"INSERT INTO acting_credits (actor_id, titles_id, character_name, role_name) \
VALUES (%s, %s, %s, %s)", row)
conn.commit()
cursor.close()
print('Done')
Replace the “user” and “password” with your own credentials. “database” refers to the target database
Data Analysis SQL Queries
Data analysis SQL queries and corresponding outputs for this project are as the following,
- Question 1:
- The list of movie and show titles released between 2010 to 2020
1
2
3
4
5
SELECT title, titles_info.release_year as release_year
FROM titles JOIN titles_info
ON (titles.titles_id = titles_info.titles_id)
WHERE release_year BETWEEN 2010 AND 2020
ORDER BY release_year;
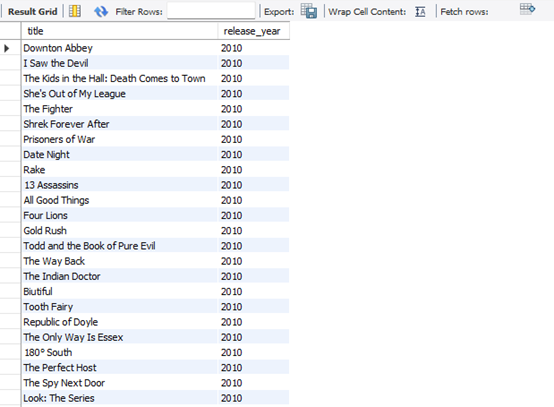 Figure 10: Snippet of The Output from The Query Analysis Question 1
Figure 10: Snippet of The Output from The Query Analysis Question 1
- Question 2:
- Which movie/show has the highest imdb score?
1
2
3
4
5
6
7
8
SELECT title, imdb_rating.imdb_score as Max_imdb_score
FROM titles JOIN imdb_rating
ON (titles.titles_id = imdb_rating.titles_id)
WHERE imdb_rating.imdb_score =
(
SELECT MAX(imdb_score)
FROM imdb_rating
);
 Figure 11: Output from The Query Analysis Question 2
Figure 11: Output from The Query Analysis Question 2
- Question 3:
- Which movie/show has the highest tmdb score?
1
2
3
4
5
6
7
8
SELECT title, tmdb_rating.tmdb_score as Max_tmdb_score
FROM titles JOIN tmdb_rating
ON (titles.titles_id = tmdb_rating.titles_id)
WHERE tmdb_rating.tmdb_score =
(
SELECT MAX(tmdb_score)
FROM tmdb_rating
);
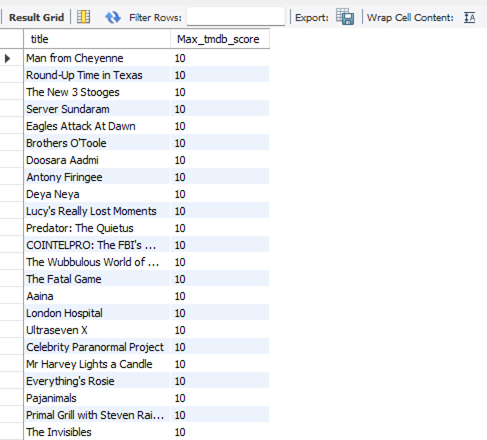 Figure 12: Snippet of The Output from The Query Analysis Question 3
Figure 12: Snippet of The Output from The Query Analysis Question 3
- Question 4:
- List of actors that played in the movie named ‘The Terrible Adventure’
1
2
3
4
5
6
7
SELECT name AS Actors_Name, title AS Movies_Title
FROM acting_credits
JOIN actors JOIN titles
ON (acting_credits.actor_id = actors.actor_id)
AND (acting_credits.titles_id = titles.titles_id)
WHERE titles.title = 'The Terrible Adventure'
AND acting_credits.role_name = 'ACTOR';
 Figure 13: Output from The Query Analysis Question 4
Figure 13: Output from The Query Analysis Question 4
- Question 5:
- List of directors
1
2
3
4
Select name AS Directors_Name, acting_credits.role_name AS Roles
FROM actors JOIN acting_credits
ON (actors.actor_id = acting_credits.actor_id)
WHERE acting_credits.role_name = 'DIRECTOR';
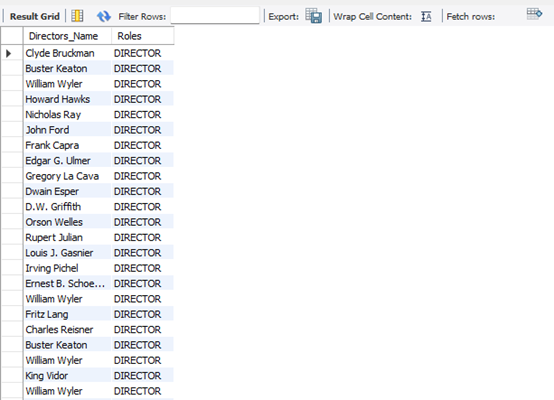 Figure 14: Snippet of The Output from The Query Analysis Question 5
Figure 14: Snippet of The Output from The Query Analysis Question 5
- Question 6:
- How many movies and shows are in the database?
1
2
3
4
SELECT COUNT(titles_id) AS Number_of_Type, type_name AS Type_Name
FROM titles_info
GROUP BY Type_Name
ORDER BY Number_of_Type;
 Figure 15: Output from The Query Analysis Question 6
Figure 15: Output from The Query Analysis Question 6
- Question 7:
- Which year has the highest and lowest movie/show production?
1
2
3
4
5
6
7
8
9
(SELECT COUNT(titles_id) AS Number_of_Production,release_year AS Years
FROM titles_info
GROUP BY Years
ORDER BY Number_of_Production ASC LIMIT 1)
UNION ALL
(SELECT COUNT(titles_id) AS Number_of_Production,release_year AS Years
FROM titles_info
GROUP BY Years
ORDER BY Number_of_Production DESC LIMIT 1);
 Figure 16: Output from The Query Analysis Question 7
Figure 16: Output from The Query Analysis Question 7
- Question 8:
- What are the movies/shows that William Wyler directed?
1
2
3
4
5
6
7
8
9
SELECT name AS Director_Name, title AS Titles, type_name AS Type_Name
FROM actors JOIN titles JOIN acting_credits JOIN titles_info
ON (actors.actor_id = acting_credits.actor_id) AND (titles.titles_id = acting_credits.titles_id) AND (acting_credits.titles_id = titles_info.titles_id)
WHERE actors.actor_id =
(
SELECT actors.actor_id
FROM actors
WHERE name LIKE 'William Wyler%'
);
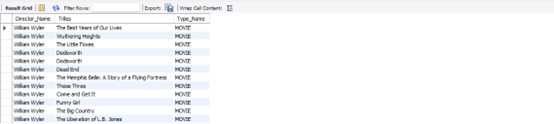 Figure 17: Output from The Query Analysis Question 8
Figure 17: Output from The Query Analysis Question 8
- Question 9:
- What are the movies with genres comedy, romance and drama?
1
2
3
4
SELECT title AS Movies_Title, genres AS Movies_Genres
FROM titles JOIN titles_info
ON (titles.titles_id = titles_info.titles_id)
WHERE genres = "['comedy', 'drama', 'romance']";
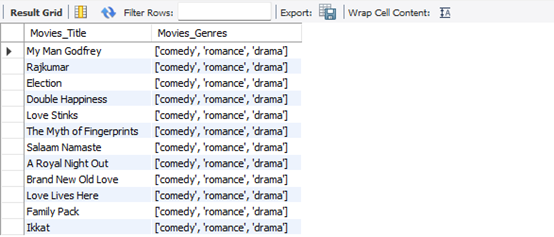 Figure 18: Output from The Query Analysis Question 9
Figure 18: Output from The Query Analysis Question 9
- Question 10:
- What are the most popular movies/shows?
1
2
3
4
SELECT title AS Movies_Title, tmdb_rating.tmdb_popularity AS Most_tmdb_popularity
FROM titles JOIN tmdb_rating
ON (titles.titles_id = tmdb_rating.titles_id)
WHERE tmdb_rating.tmdb_popularity = (SELECT MAX(tmdb_popularity) FROM tmdb_rating);
 Figure 19: Output from The Query Analysis Question 10
Figure 19: Output from The Query Analysis Question 10
- Question 11:
- What are the movies that have runtime >100 minutes and the production is in the US?
1
2
3
4
5
SELECT title, titles_info.runtime AS Runtime, titles_info.production_countries AS Prouduction
FROM titles JOIN titles_info
ON (titles.titles_id = titles_info.titles_id)
WHERE runtime > 100 AND production_countries = "['US']" AND type_name = 'MOVIE'
ORDER BY runtime ASC;
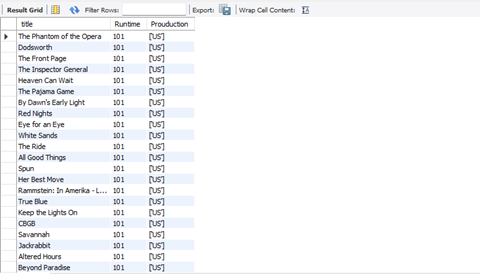 Figure 20: Snippet of The Output from The Query Analysis Question 11
Figure 20: Snippet of The Output from The Query Analysis Question 11
- Question 12:
- What are the movies and shows in 2020 where the imbd_score is more than 7.5?
1
2
3
4
5
SELECT title, titles_info.release_year AS Release_Year, imdb_score
FROM titles JOIN titles_info JOIN imdb_rating
ON (titles.titles_id = titles_info.titles_id) AND (titles.titles_id = imdb_rating.titles_id)
WHERE release_year = 2020 AND imdb_score > 7.5
ORDER BY imdb_score ASC;
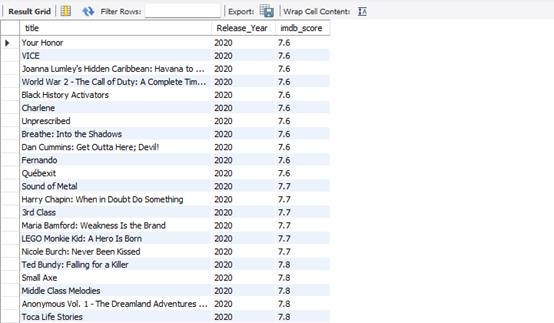 Figure 21: Snippet of The Output from The Query Analysis Question 12
Figure 21: Snippet of The Output from The Query Analysis Question 12
- Question 13:
- What are the PG classified movies from 2020 to 2021?
1
2
3
4
5
SELECT title, titles_info.age_certification AS Age_Classified, titles_info.release_year AS Release_Year
FROM titles JOIN titles_info
ON (titles.titles_id = titles_info.titles_id)
WHERE age_certification = 'PG' AND release_year BETWEEN 2020 AND 2021
ORDER BY release_year ASC;
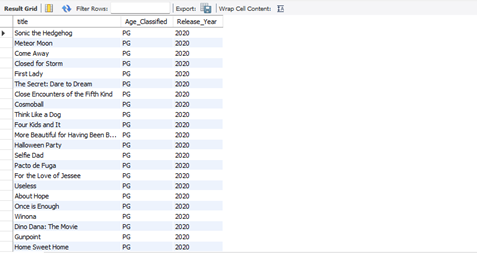 Figure 22: Snippet of The Output from The Query Analysis Question 13
Figure 22: Snippet of The Output from The Query Analysis Question 13
The dataset, SQL script, Python script and ERD Model mentioned in this article are hosted in my Github Repo