
The following article is a part of my Big Data Management Project for NoSQL via MongoDB. The first part of the project was done entirely in SQL and the details for that can be accessed here. Several terms need to be defined clearly to get a clear understanding on the operations of MongoDB, which are,
- Documents: Similar to records or rows in a relational database table
- Collections: A collection holds one or more documents, similar like a table
- Database: Stores one or more collections of documents
For reference, Figure 1 illustrates the Entity Relationship Diagram (ERD) used in the previous SQL Project.
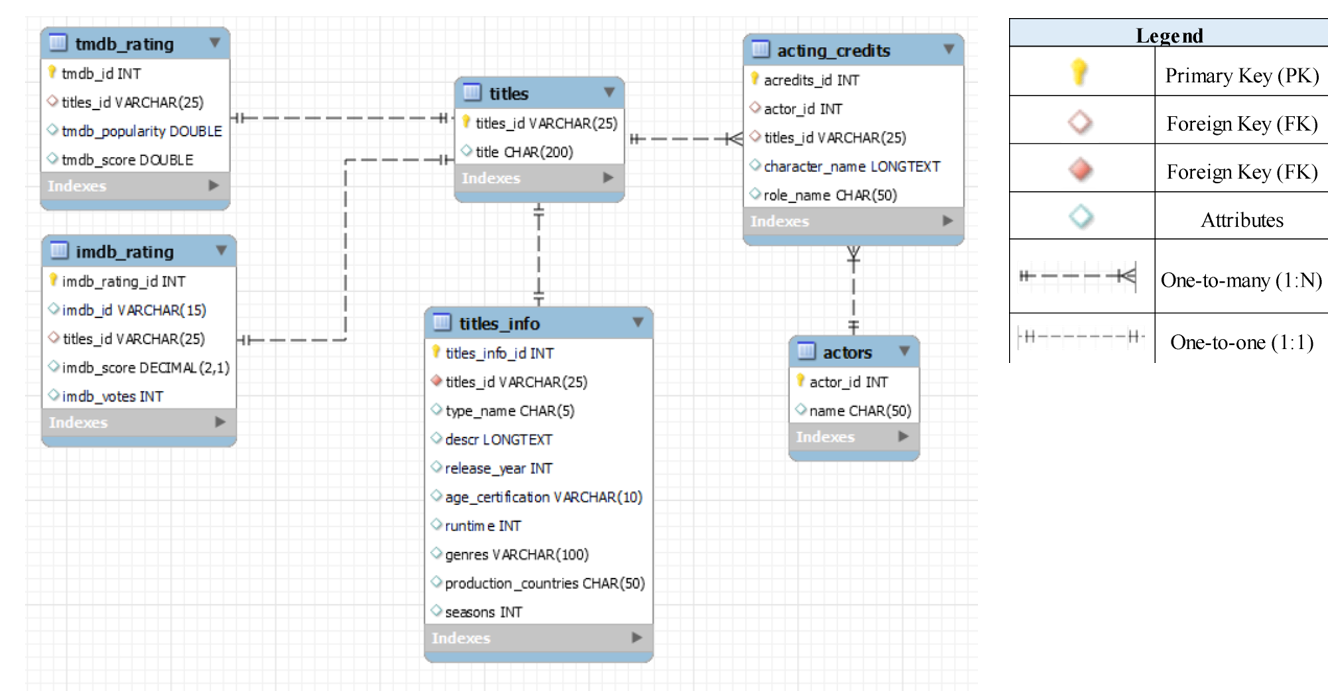 Figure 1: The Entity Relationship Diagram (ERD)
Figure 1: The Entity Relationship Diagram (ERD)
From Figure 1, it is understood that there are 6 tables and the process of converting these tables from MySQL into MongoDB Compass can be broken down into the steps below,
(a) The first step is to export the data from MySQL into a local file. The format can either be in .csv or .json. For the purposes of this project, .json is used as the format. The step is illustrated in Figure 2.
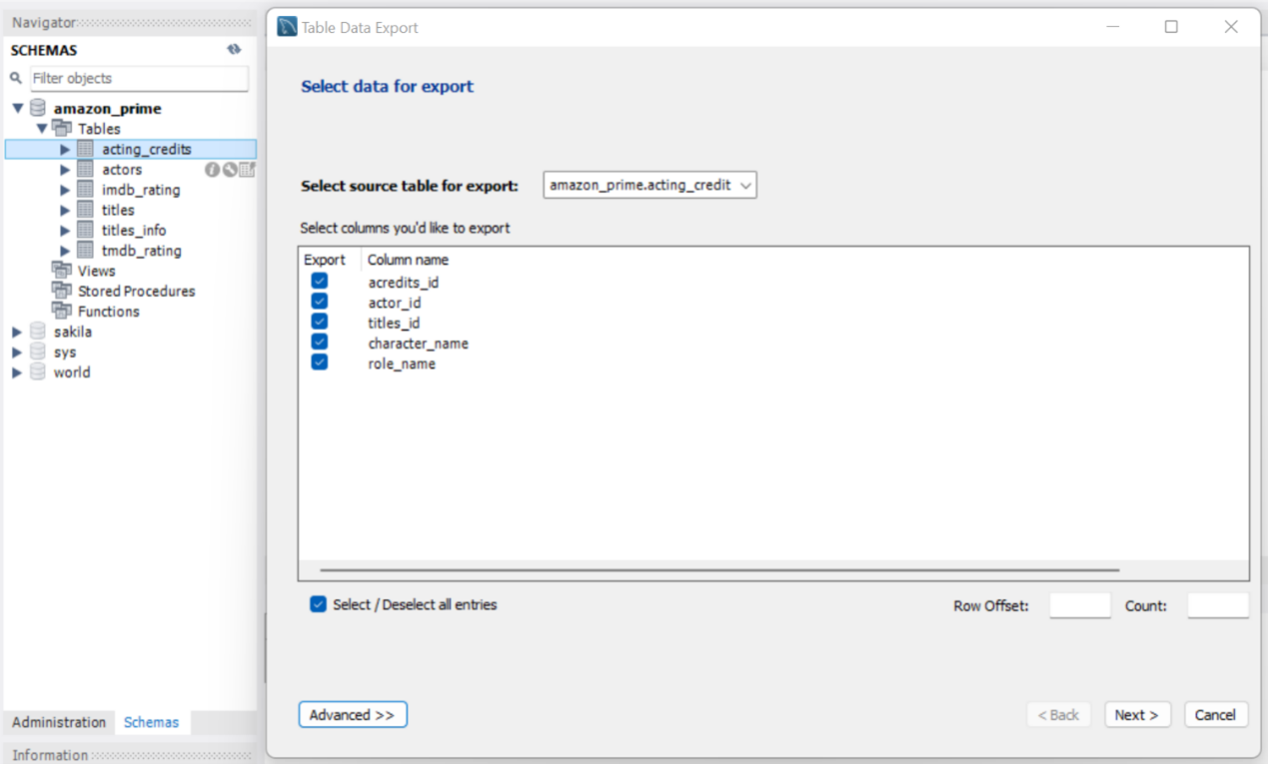 Figure 2: Converting Step 1 - Export Data from MySQL
Figure 2: Converting Step 1 - Export Data from MySQL
(b) The following steps would be to import the exported data from MySQL into MongoDB Compass. This is done by first creating a database in MongoDB Compass according to the specified name which is followed by the creation of a collection. Once this is done, data in the form of .json will be imported into the collection. These steps will have to be repeated for all collections. The steps mentioned here are depicted in Figure 3 and Figure 4.
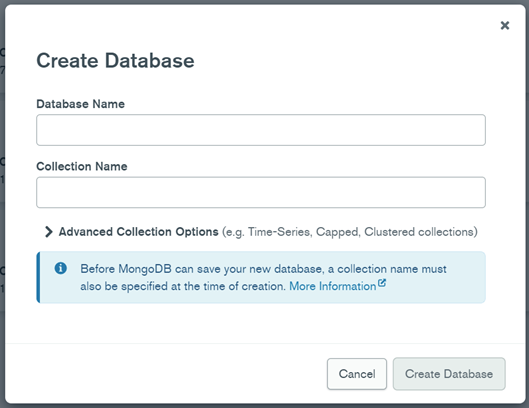 Figure 3: Converting Step 2 - Create Database and Collection in MongoDB Compass
Figure 3: Converting Step 2 - Create Database and Collection in MongoDB Compass
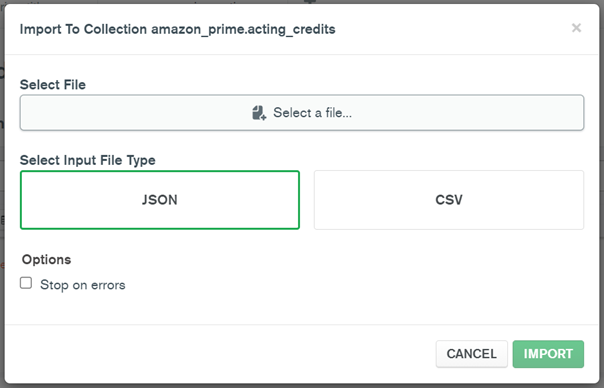 Figure 4: Converting Step 3 - Import .json Data into Collections
Figure 4: Converting Step 3 - Import .json Data into Collections
Following the steps from Figure 2, Figure 3 and Figure 4, it will result in 6 collections under a database which is in the form of referenced documents, contrary to embedded documents. Below are the explanations on the differences between the two types,
- Embedded Documents: Embedded documents are stored as children inside a parent document. This means that they are all stored under one collection, and whenever a retrieval is done on the parent document, all its embedded documents will be retrieved as well. Figure 5 illustrates the working example of this where the collection “titles” is embedded in the collection “titles_info”.
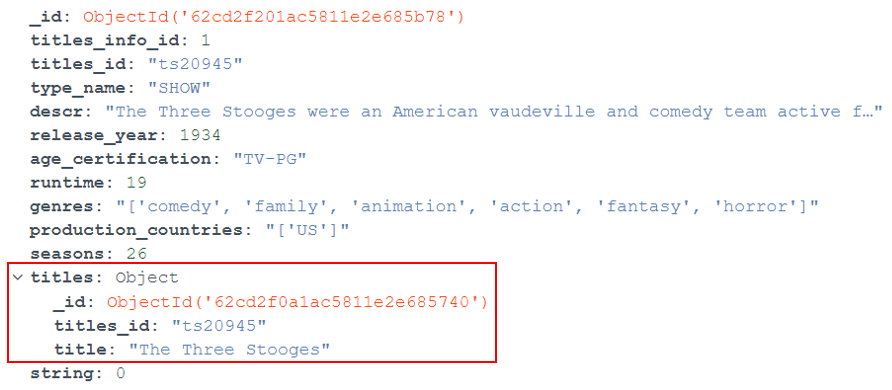 Figure 5: Embedded Document Example
Figure 5: Embedded Document Example
- Referenced Documents: Unlike embedded documents shown above, referenced documents are stored in a separate collection to their parent document. This means that, it will be possible to retrieve the parent document without retrieving any of its referenced documents. To retrieve information from other collections it is possible in MongoDB Compass to use the $lookup function. Figure 6 depicts an example of referenced document containing the same information as Figure 6.
 Figure 6: Referenced Document Example
Figure 6: Referenced Document Example
As stated in MongoDB manual, data in MongoDB has a flexible schema which means that collections do not enforce document structure by default. This flexibility gives us data modeling choices to match the particular application and its performance requirements. Below is the breakdown on the choices and justification on using embedded or reference documents.
If the particular application requires massive write operation without the need to read the entire parent document, references is a better choice. Embedded documents for this case will result in write operation consuming time, predominantly due to the need to serialize/deserialize the entire document each time.
If the particular application requires reading and using the majority of the data in a document and its related documents, store them together as embedded documents. Using index queries can greatly improve read times here. Storing them as references will just unnecessarily increase response times due to more queries being executed than needed.
A hybrid approach by mixing the two methods may also be done depending on the requirements of the application. Write intensive operations shall be stored as reference while read intensive operations shall be stored as embedded documents.
MongoDB Queries
The queries and corresponding outputs for this project are as the following,
- Question 1:
- The list of movie and show titles released between 2010 to 2020
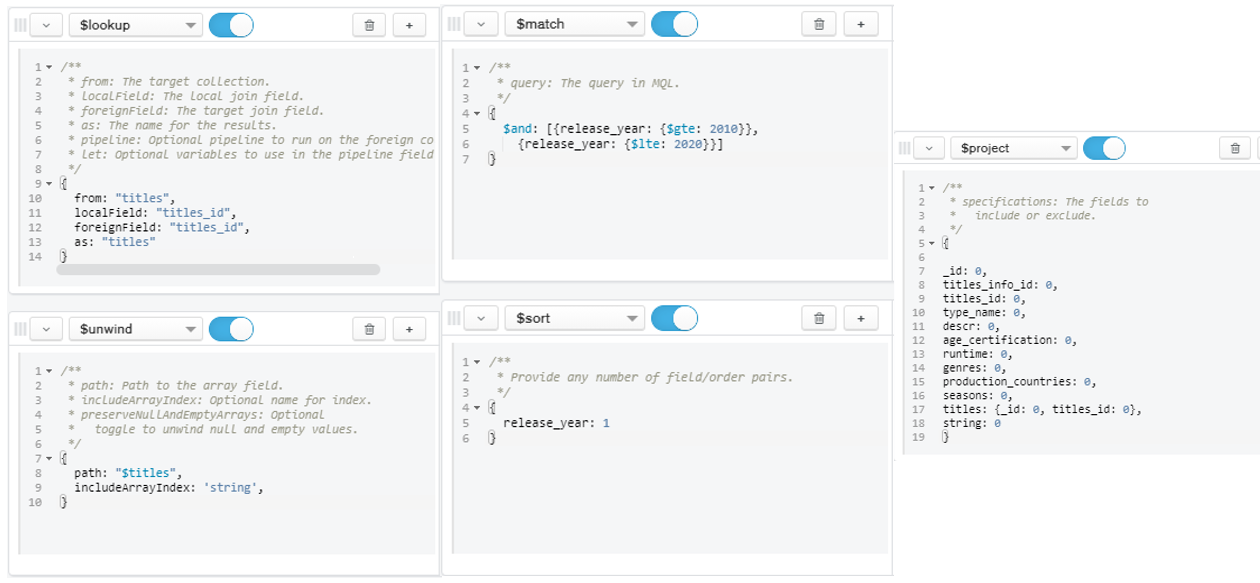 Figure 7: Query for Question 1
Figure 7: Query for Question 1
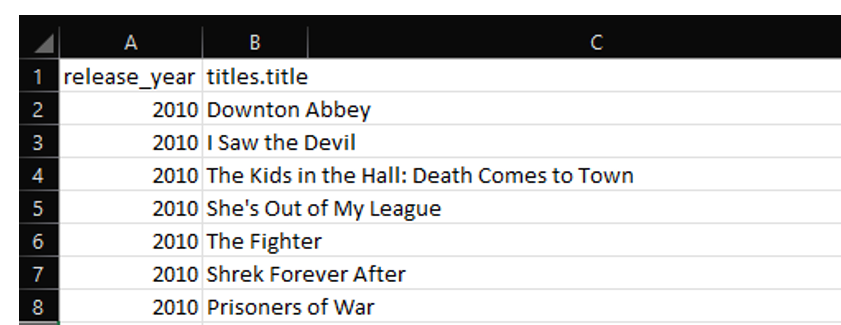 Figure 8: Snippet of Output for Question 1
Figure 8: Snippet of Output for Question 1
- Question 2:
- Which movie/show has the highest imdb score?
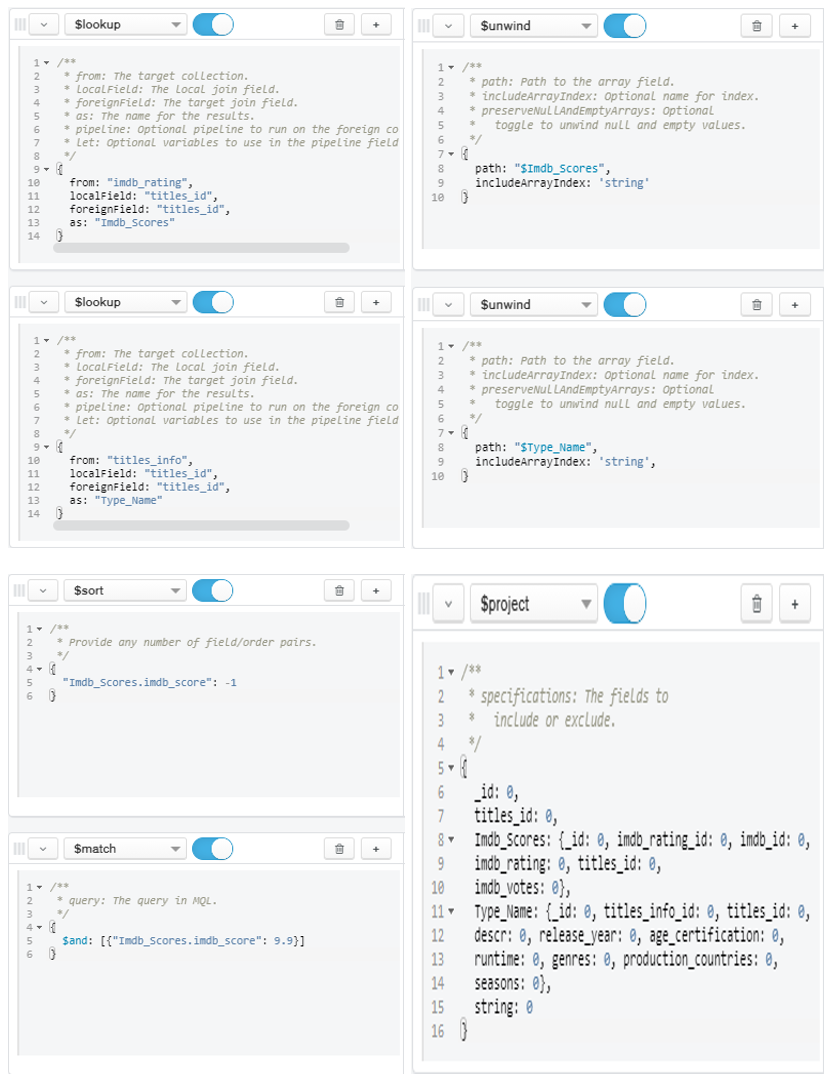 Figure 9: Query for Question 2
Figure 9: Query for Question 2
 Figure 10: Snippet of Output for Question 2
Figure 10: Snippet of Output for Question 2
- Question 3:
- Which movie/show has the highest tmdb score?
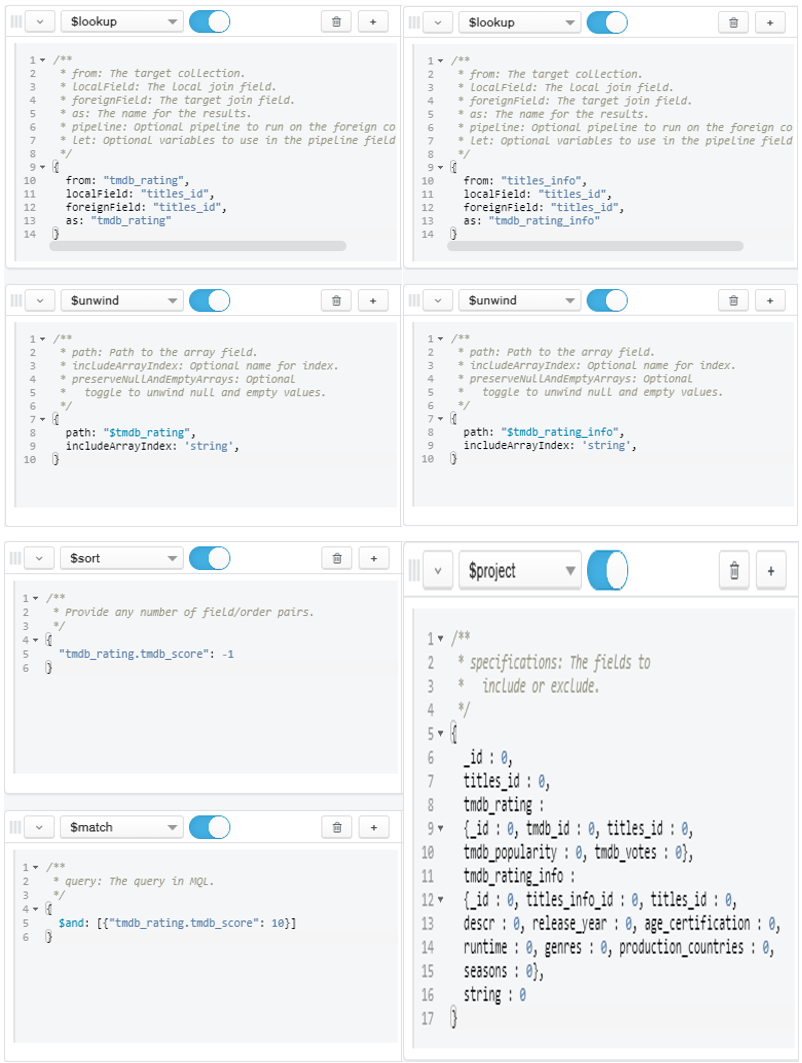 Figure 11: Query for Question 3
Figure 11: Query for Question 3
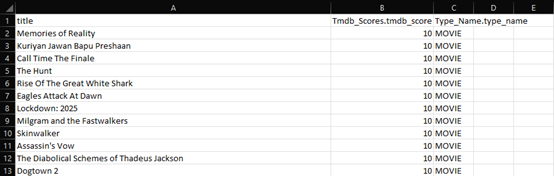 Figure 12: Snippet of Output for Question 3
Figure 12: Snippet of Output for Question 3
- Question 4:
- List of actors that played in the movie named ‘The Terrible Adventure’
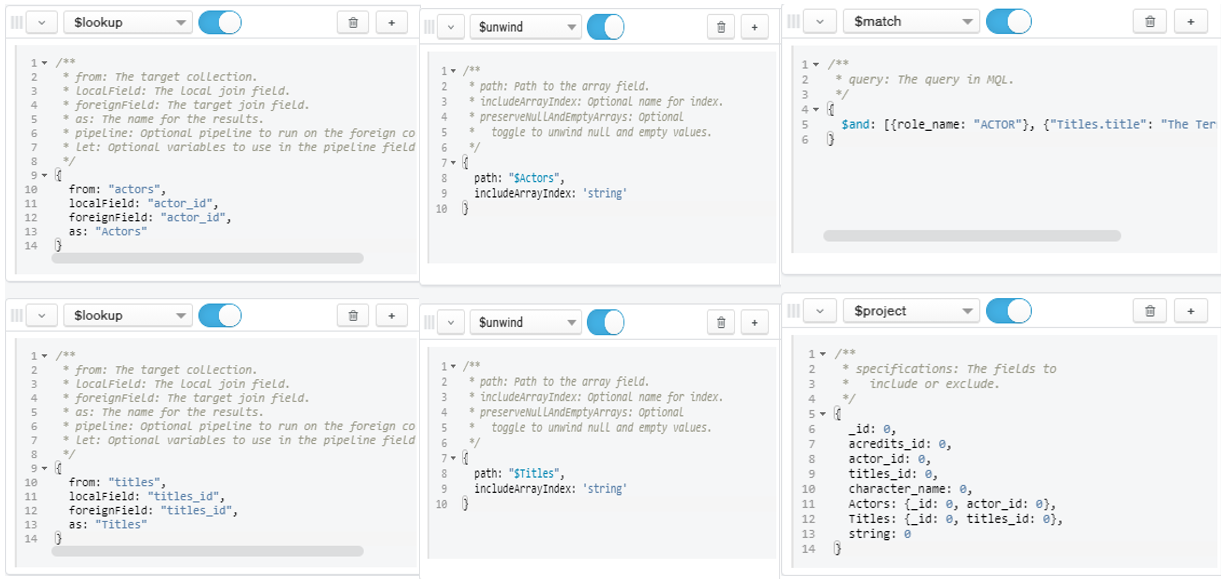 Figure 13: Query for Question 4
Figure 13: Query for Question 4
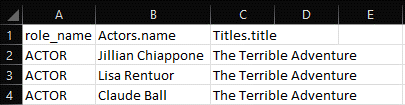 Figure 14: Snippet of Output for Question 4
Figure 14: Snippet of Output for Question 4
- Question 5:
- List of directors
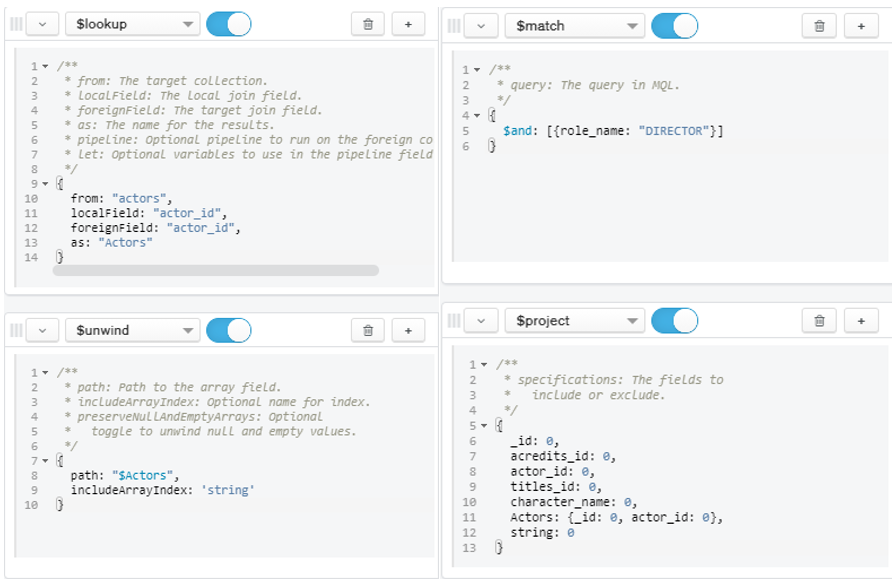 Figure 15: Query for Question 5
Figure 15: Query for Question 5
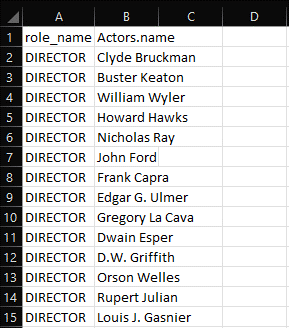 Figure 16: Snippet of Output for Question 5
Figure 16: Snippet of Output for Question 5
- Question 6:
- How many movies and shows are in the database?
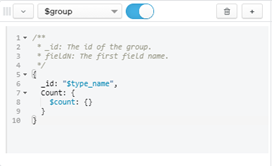 Figure 17: Query for Question 6
Figure 17: Query for Question 6
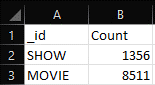 Figure 18: Snippet of Output for Question 6
Figure 18: Snippet of Output for Question 6
- Question 7:
- Which year has the highest and lowest movie/show production?
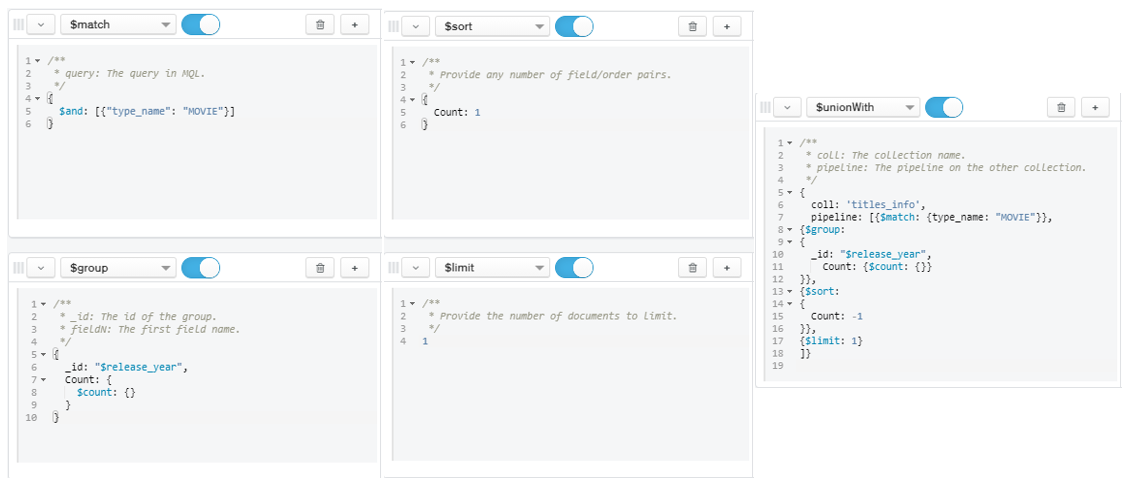 Figure 19: Query for Question 7
Figure 19: Query for Question 7
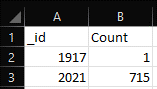 Figure 20: Snippet of Output for Question 7
Figure 20: Snippet of Output for Question 7
- Question 8:
- What are the movies/shows that William Wyler directed?
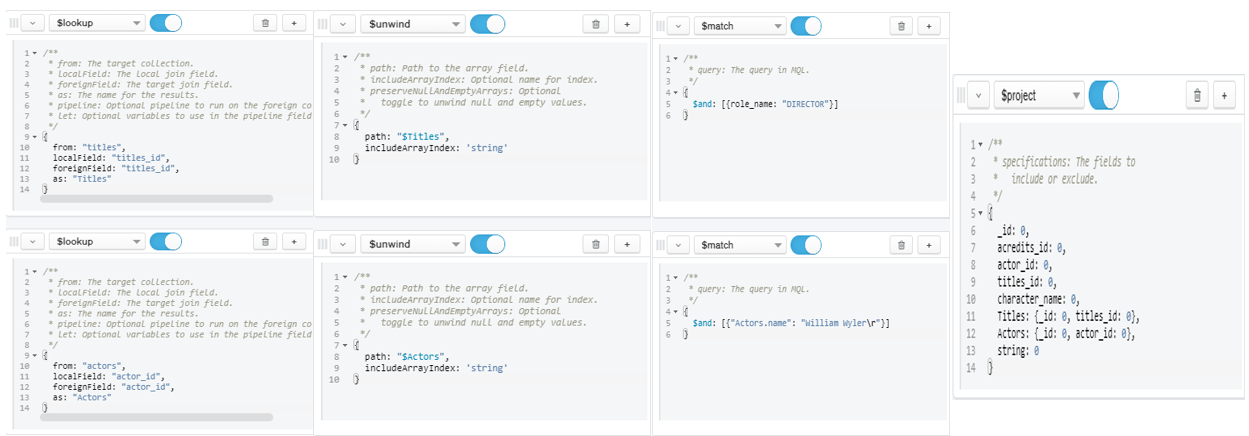 Figure 21: Query for Question 8
Figure 21: Query for Question 8
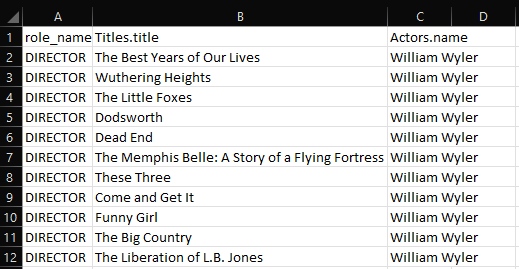 Figure 22: Snippet of Output for Question 8
Figure 22: Snippet of Output for Question 8
- Question 9:
- What are the movies with genres [‘comedy’,’drama’,’romance’]?
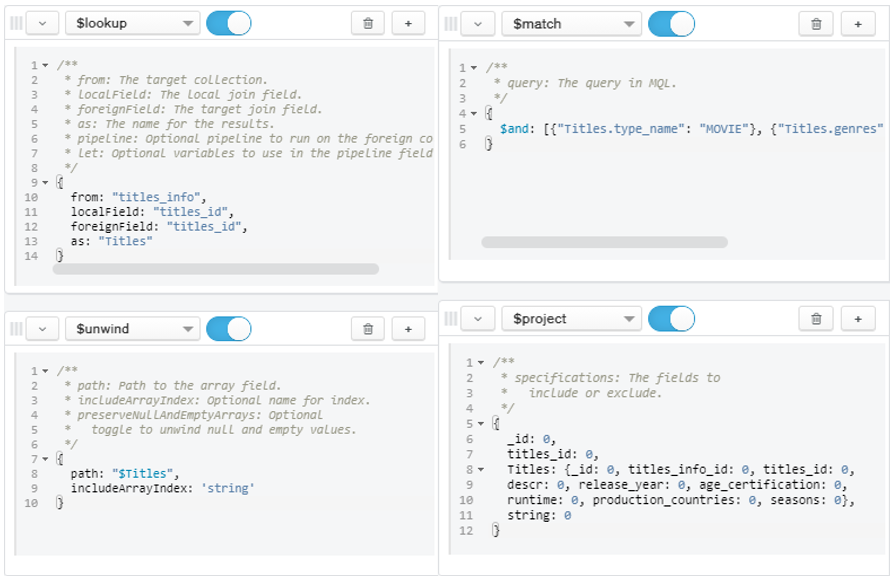 Figure 23: Query for Question 9
Figure 23: Query for Question 9
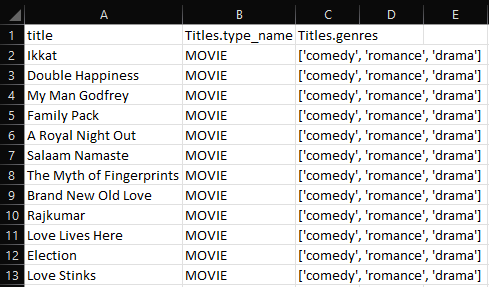 Figure 24: Snippet of Output for Question 9
Figure 24: Snippet of Output for Question 9
- Question 10:
- What is the most popular movies/shows?
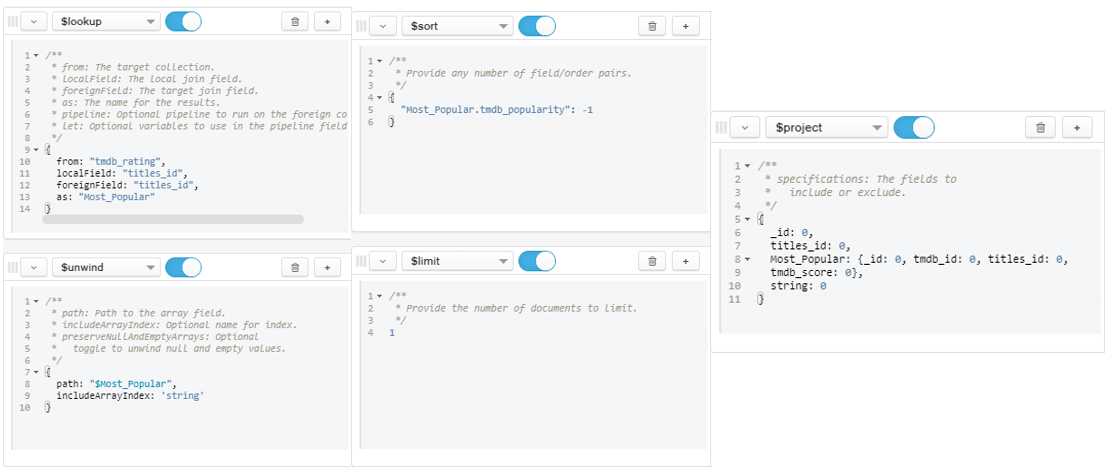 Figure 25: Query for Question 10
Figure 25: Query for Question 10
 Figure 26: Snippet of Output for Question 10
Figure 26: Snippet of Output for Question 10
- Question 11:
- What are the movies that have runtime >100 minutes and the production is in the [‘US’]?
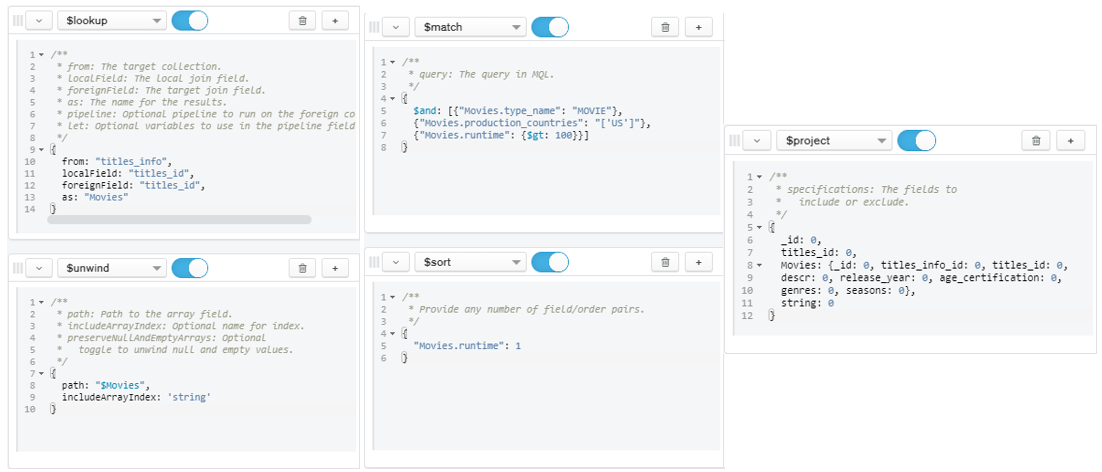 Figure 27: Query for Question 11
Figure 27: Query for Question 11
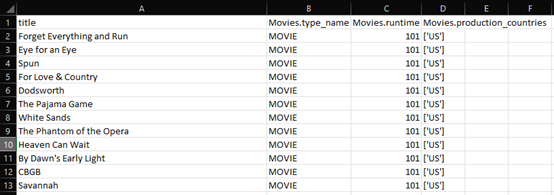 Figure 28: Snippet of Output for Question 11
Figure 28: Snippet of Output for Question 11
- Question 12:
- What are the movies and shows in 2020 where the imbd_score is more than 7.5?
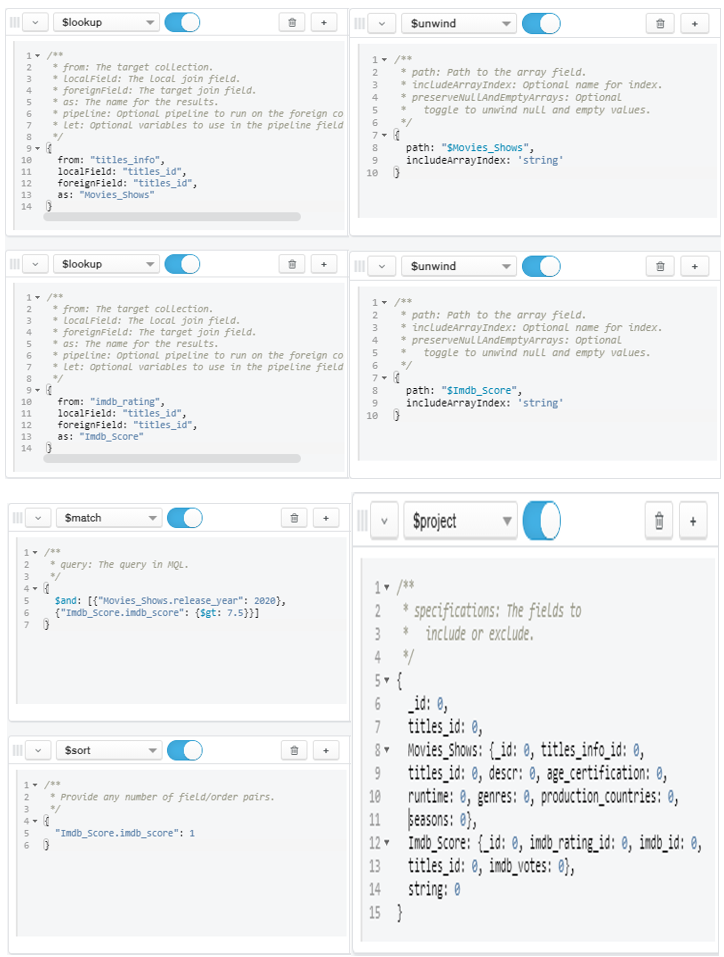 Figure 29: Query for Question 12
Figure 29: Query for Question 12
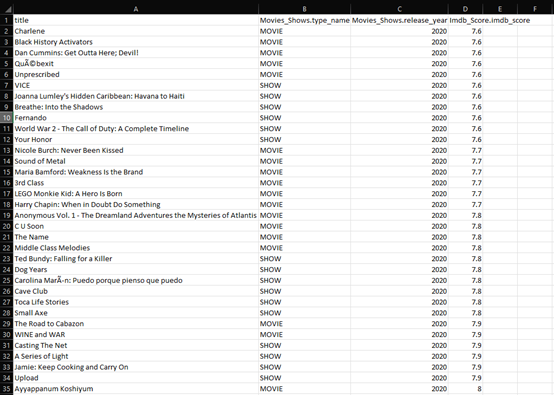 Figure 30: Snippet of Output for Question 12
Figure 30: Snippet of Output for Question 12
- Question 13:
- What are the PG classified movies from 2020 to 2021?
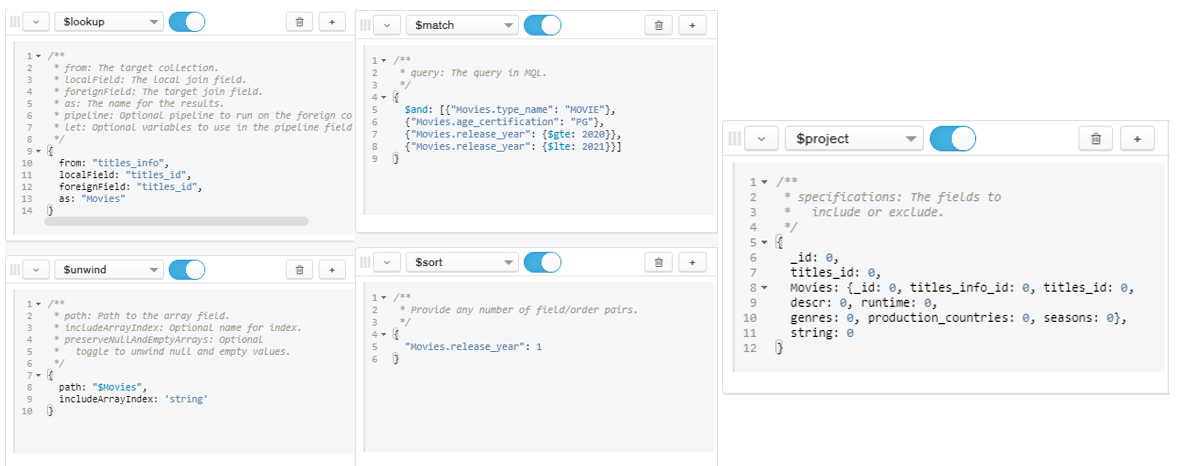 Figure 31: Query for Question 13
Figure 31: Query for Question 13
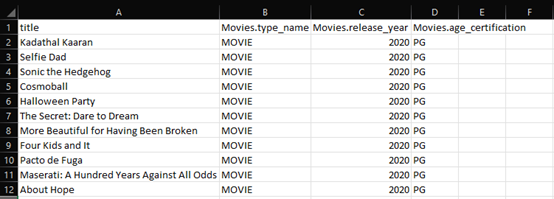 Figure 32: Snippet of Output for Question 13
Figure 32: Snippet of Output for Question 13
MongoDB Queries
MongoDB employs indexing to speed up the response time to queries. If there is no indexing, MongoDB will have to scan every document in the collection and only return the ones that are relevant to the query. Indexes are specialized data structures that store some document-related data to make it simpler for MongoDB to locate the correct data file. The indexes are arranged according to the value of the field that each index specifies. Below are the step-by-step to create index query for question analysis 1: The list of movie and show titles released between 2010 to 2020?
(a) Figure 33 shows the query to create new collection for index query.
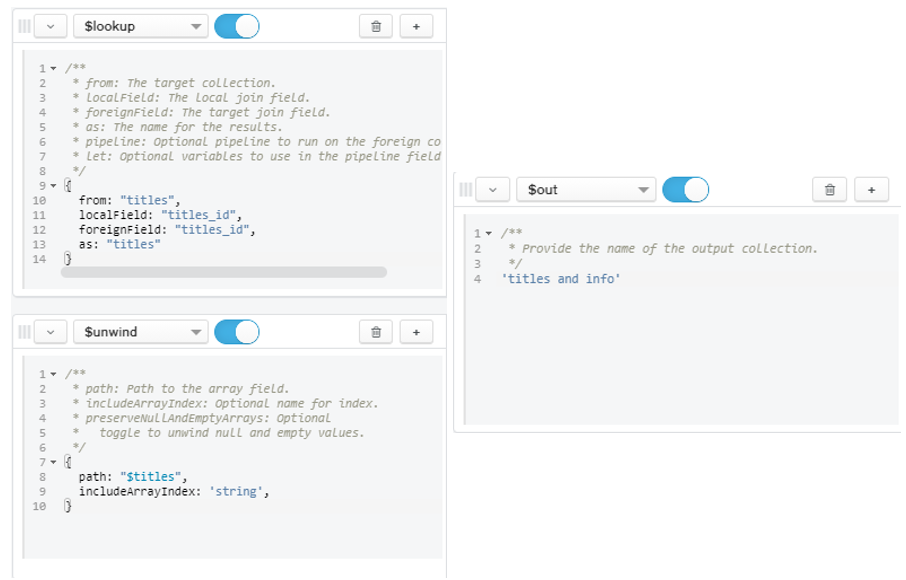 Figure 33: Query to Create New Collection for Index Query
Figure 33: Query to Create New Collection for Index Query
(b) Figure 34 shows the indexes tab on the new collection, ‘titles and info’ as created in the step 1. Click ‘CREATE INDEX’.
 Figure 34: The Index Tab on The New Collection (titles and info)
Figure 34: The Index Tab on The New Collection (titles and info)
(c) Figure 35 shows Create Index panel where the indexes are created. Under the dropdown menu, ‘Select or type a field name’, choose the field name. For this question, the field names are ‘release_year’ and ‘type_name’. Then, under the dropdown menu, ‘Select a type’, choose ‘1 (asc)’ for both chosen field names. Click, ‘CREATE INDEX’.
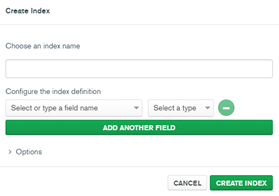 Figure 35: Create Index Panel
Figure 35: Create Index Panel
(d) Figure 36 shows the indexes that have been created on the Index Tab. Click ‘Explain Plan’ tab to see the query performance summary.
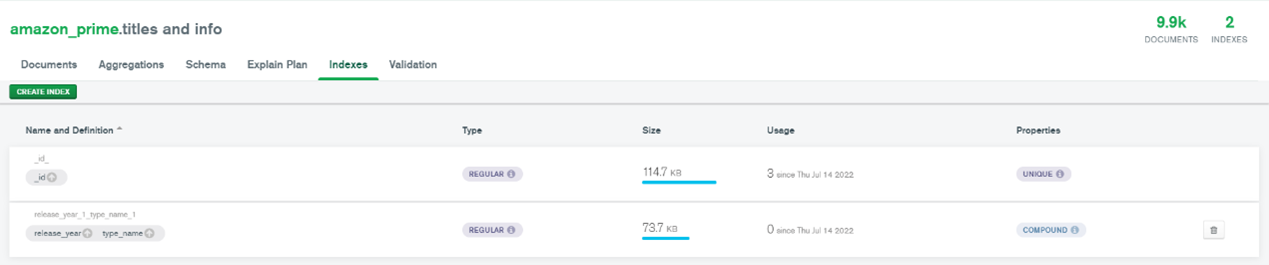 Figure 36: Created Indexes on Indexes Tab
Figure 36: Created Indexes on Indexes Tab
Figure 37 shows the Query Performance Summary if the indexes are not created, while Figure 38 shows the Query Performance Summary when the indexes are created. When the indexes are not created, the execution time taken by the query is longer compared to the query with the indexes, which are 24 ms and 18 ms, respectively. The documents examined by the query without indexes are also more compared to the query with indexes which are 9,867 and 4,164, respectively.
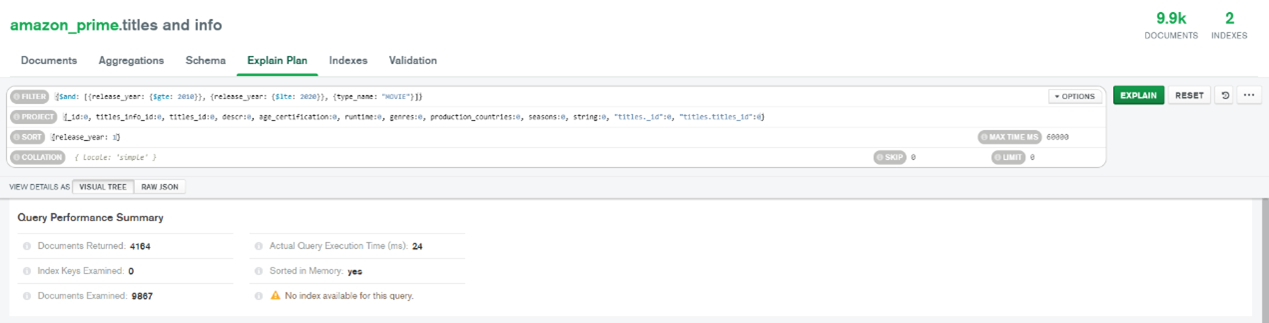 Figure 37: Query Performance Summary without Indexes
Figure 37: Query Performance Summary without Indexes
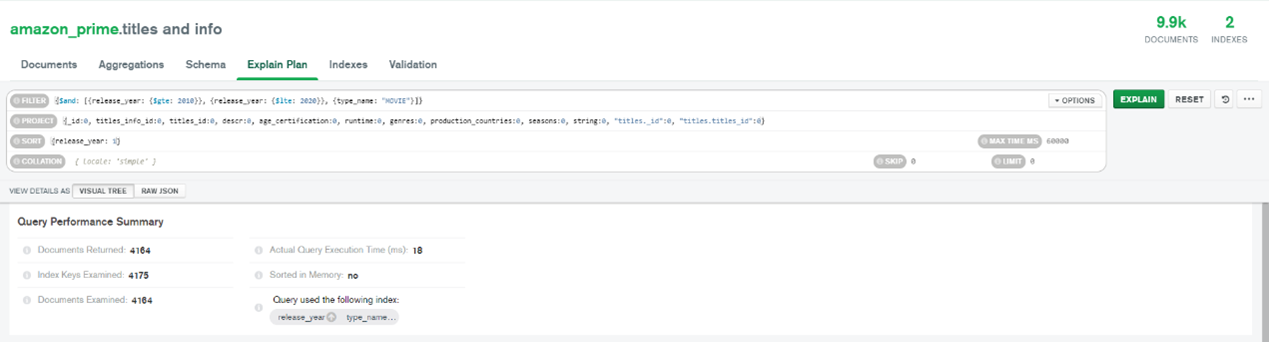 Figure 38: Query Performance Summary with Indexes
Figure 38: Query Performance Summary with Indexes
The data files, MongoDB queries and output files mentioned in this article are hosted in my Github Repo